
If you’ve spent any time around artificial intelligence in the last few years, you’ve probably noticed a strange pattern. Teams proudly announce a working AI model. Demos look impressive. Early users are excited. And then—quietly—the momentum stalls.
Latency creeps up. Costs spike. Accuracy degrades in production. Engineers argue with product teams. Leaders start asking uncomfortable questions like, “Why doesn’t this work as well as it did in the demo?”
This is where scaling AI becomes the real story.
Building an AI model is no longer the hard part. Scaling AI—reliably, affordably, and responsibly across real users, real data, and real business constraints—is where most initiatives succeed or fail. The difference between a clever experiment and a revenue-generating, trust-worthy AI system lives entirely in how well it scales.
This article is written for founders, product leaders, engineers, data scientists, and decision-makers who are past the hype stage. You already believe AI matters. What you need now is clarity on how to grow it without breaking performance, budgets, or trust.
We’ll move from beginner-friendly explanations to expert-level, real-world strategies. You’ll learn what scaling AI actually means, why it’s so difficult, where most teams go wrong, and how experienced organizations approach it differently. By the end, you’ll have a practical mental model you can apply whether you’re scaling a single internal tool or a global AI-powered platform.
What Scaling AI Really Means (And What It Definitely Doesn’t)
Scaling AI is often misunderstood because people borrow definitions from traditional software. In classic software, scaling usually means handling more users or more traffic by adding servers. AI doesn’t work that way.
At its core, scaling AI means increasing the scope, impact, and reliability of intelligent systems while maintaining—or improving—performance, cost efficiency, and outcomes as complexity grows.
A helpful analogy is a restaurant kitchen. Cooking one excellent dish is different from running a restaurant that serves hundreds of meals per hour without sacrificing quality. AI models behave the same way. They can perform beautifully in controlled environments but struggle once exposed to noisy data, unpredictable users, and evolving requirements.
Scaling AI includes multiple dimensions at once:
- Data scale: More volume, more variety, and faster data streams
- Model scale: Larger or more complex models, or many models working together
- User scale: More requests, more edge cases, more expectations
- Operational scale: Monitoring, updates, governance, and compliance
- Organizational scale: Teams, workflows, and decision-making structures
What scaling AI does not mean is blindly making models bigger or throwing more compute at the problem. That approach often increases costs and fragility without delivering better results.
True scaling is about balance. You are constantly trading off speed, accuracy, cost, reliability, and risk. Teams that understand this early design for scale from the beginning—even when they start small.
Why Scaling AI Matters Right Now More Than Ever
Five years ago, AI adoption was mostly experimental. Today, AI systems are embedded in customer support, healthcare diagnostics, finance, marketing, logistics, and internal decision-making. When these systems fail, the consequences are no longer theoretical.
Scaling AI matters now because:
First, usage expectations have changed. Users expect AI tools to be instant, accurate, and always available. A five-second delay or a sudden drop in quality feels unacceptable.
Second, data environments are more dynamic. Models trained on last year’s data degrade faster than ever as user behavior, markets, and language evolve.
Third, regulatory and ethical scrutiny is increasing. Scaling an AI system also means scaling accountability, transparency, and compliance.
Finally, competition is fierce. Organizations that scale AI successfully compound their advantages. Those that don’t often abandon promising initiatives after expensive failures.
In practical terms, scaling AI determines whether your investment becomes a long-term asset or an ongoing liability.
Who Benefits Most From Scaling AI (And How)
Almost every industry touches AI now, but the benefits of scaling AI show up differently depending on context.
In SaaS and tech products, scaling AI enables personalization at scale. Recommendation systems, search, fraud detection, and copilots become more accurate as usage grows—if they are designed correctly.
In enterprises, scaling AI reduces operational bottlenecks. Automated document processing, forecasting, and internal assistants free human teams for higher-value work.
In startups, scaling AI can be the entire business model. What starts as a narrow tool becomes a platform that adapts to new customers and use cases without rebuilding everything from scratch.
The real-world outcomes are tangible:
Before scaling AI properly, teams deal with frequent outages, manual interventions, unpredictable costs, and inconsistent results.
After scaling AI successfully, systems become boring in the best way possible. They work. They adapt. They improve quietly in the background while teams focus on strategy and growth.
The Hidden Layers of Scaling AI Most People Miss
One reason scaling AI feels so difficult is that the challenges are rarely visible in early prototypes.
Early-stage AI systems often rely on clean datasets, limited users, and constant human supervision. These conditions disappear in production. Suddenly, data arrives late or malformed. Users ask unexpected questions. Models face inputs they were never trained on.
Another hidden layer is organizational. AI scaling is not just a technical problem. It requires coordination between data teams, infrastructure teams, legal, security, and business stakeholders. Without clear ownership and shared metrics, systems stagnate.
There’s also the psychological layer. Teams fall in love with their models. When performance degrades, they assume the model needs retraining, when the real issue is data pipelines, feedback loops, or system design.
Understanding these layers early helps you avoid chasing the wrong solutions.
A Practical, Step-by-Step Framework for Scaling AI

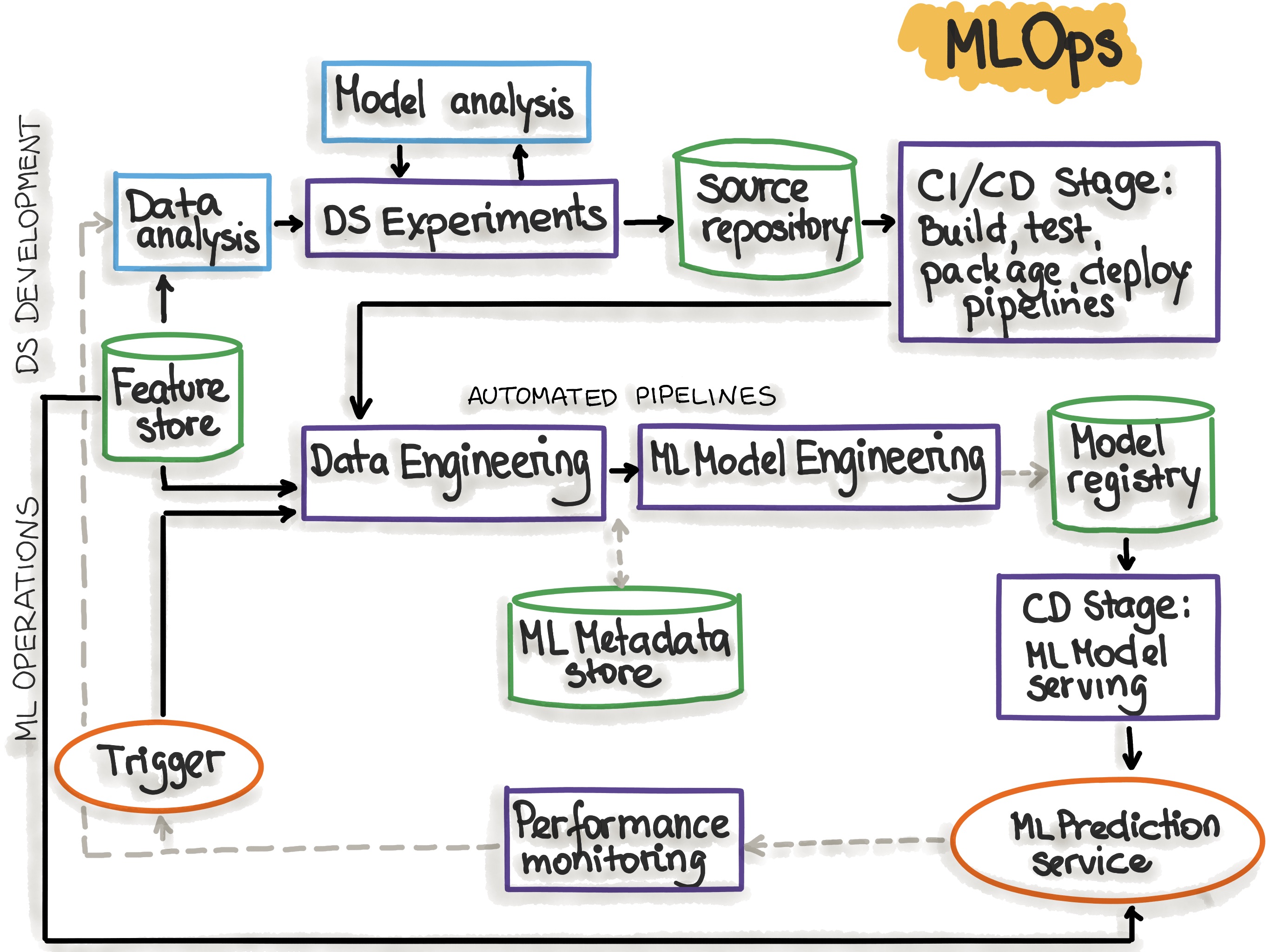
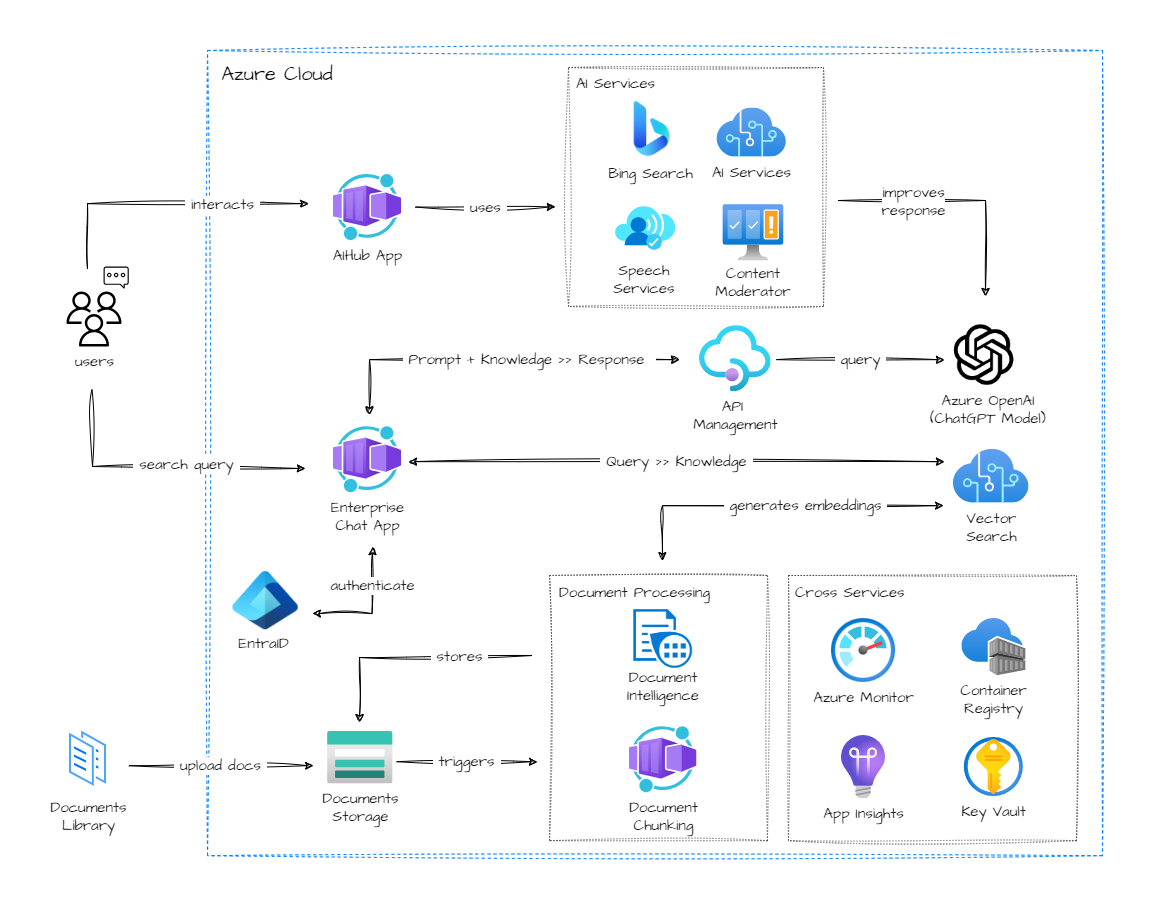
Step 1: Define What “Scale” Means for Your Use Case
Before touching infrastructure, get specific. Scaling AI for a chatbot is different from scaling AI for medical imaging.
Ask questions like:
- How many requests per second must the system handle?
- What latency is acceptable?
- What happens when the model is wrong?
- How fast does the data change?
These answers shape every technical decision that follows.
Step 2: Build for Observability From Day One
You cannot scale what you cannot see. Observability means tracking not just uptime, but model behavior.
Effective AI systems monitor:
- Input data drift
- Prediction confidence
- Error rates by segment
- Latency and cost per request
This is where many teams fail. They monitor servers but ignore models, only discovering problems when users complain.
Step 3: Separate Models From Products
A scalable AI system treats models as interchangeable components, not hard-coded logic.
This allows you to:
- Swap models without redeploying the entire product
- Run A/B tests safely
- Roll back quickly when performance drops
This separation is foundational for long-term scalability.
Step 4: Automate Retraining and Validation
Manual retraining doesn’t scale. At some point, models must update themselves based on new data—within guardrails.
Automation doesn’t mean removing humans. It means humans set policies, thresholds, and approval steps while machines handle repetition.
Step 5: Design for Cost as a First-Class Metric
AI systems can quietly become expensive. Scaling AI responsibly means understanding cost per prediction and how it changes with usage.
Teams that succeed bake cost awareness into architecture, choosing lighter models when possible and reserving heavy computation for high-value scenarios.
Tools and Platforms That Actually Help With Scaling AI
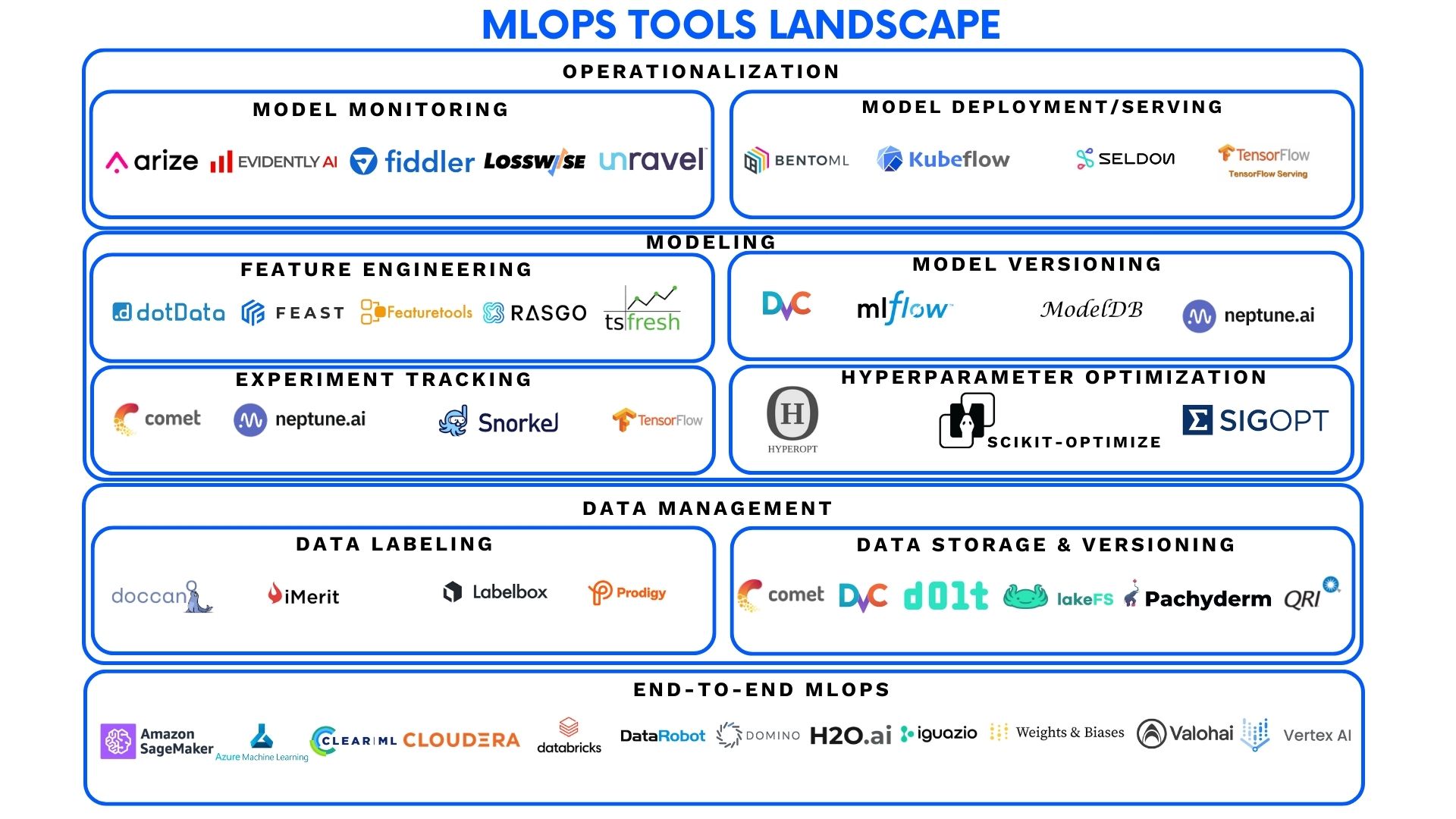


There is no single “best” tool for scaling AI. What matters is fit.
Lightweight teams often start with managed platforms that handle deployment and monitoring with minimal setup. These are ideal for speed and small teams but can become limiting at scale.
More mature organizations adopt modular stacks that separate data ingestion, training, deployment, and monitoring. This approach offers flexibility but requires stronger engineering discipline.
When evaluating tools, experienced practitioners focus less on features and more on failure modes:
- How easy is rollback?
- What happens when data pipelines break?
- Can non-experts understand alerts?
The best tools fade into the background. They support decision-making instead of demanding constant attention.
Common Scaling AI Mistakes (And How to Fix Them)
One of the most common mistakes is assuming a single model can handle everything. In reality, scalable systems often use multiple specialized models coordinated by simple logic.
Another frequent issue is ignoring edge cases until users complain. At scale, edge cases become the norm. Systems must be designed to fail gracefully, escalating to humans when confidence is low.
Teams also underestimate organizational friction. Without clear ownership, models stagnate. Successful scaling efforts assign responsibility not just for building models, but for maintaining outcomes over time.
The fix is rarely a single tool or technique. It’s a mindset shift from “build and deploy” to “operate and evolve.”
Ethical, Regulatory, and Trust Considerations at Scale
As AI systems scale, so do their consequences. Bias that affects a few users in testing can affect millions in production.
Responsible scaling AI means embedding checks for fairness, explainability, and user consent into the system—not bolting them on later.
Transparency builds trust. Users are more forgiving of limitations when systems communicate uncertainty clearly instead of pretending to be perfect.
Organizations that treat ethics as part of scaling—not an obstacle—are better positioned for long-term success.
The Future of Scaling AI: What Comes Next
Looking ahead, scaling AI will become less about raw model size and more about orchestration. Smaller, specialized models working together will outperform monolithic systems in many contexts.
We’ll also see greater emphasis on human-AI collaboration. The most scalable systems won’t replace people; they’ll amplify them.
Finally, tooling will mature. Practices that feel advanced today will become standard tomorrow, raising the baseline for what “good” looks like.
Conclusion: Scaling AI Is a Discipline, Not a Shortcut
Scaling AI is not a single milestone you reach. It’s an ongoing discipline that blends engineering, product thinking, and operational maturity.
Teams that succeed accept that models will change, data will drift, and requirements will evolve. They design systems that adapt instead of breaking under pressure.
If you’re serious about AI as a long-term capability—not just a demo—start thinking about scale earlier than feels necessary. The effort compounds, and so do the rewards.
The gap between AI experiments and AI businesses is wide, but it’s crossable. With the right mindset and practices, scaling AI becomes less of a gamble and more of a competitive advantage.
FAQs
What does scaling AI mean in simple terms?
Scaling AI means making intelligent systems work reliably for more users, more data, and more use cases without losing performance or control.
Why do AI models perform worse in production?
Real-world data is messier than training data. Scaling AI requires monitoring and adapting to data drift and unexpected behavior.
Is scaling AI only about infrastructure?
No. Infrastructure matters, but workflows, monitoring, governance, and team structure are just as important.
Can small teams scale AI effectively?
Yes, with the right abstractions and managed tools. Many failures come from overengineering too early, not under-resourcing.
How long does it take to scale an AI system properly?
It’s an ongoing process. Most teams iterate over months, improving reliability and efficiency step by step.
Adrian Cole is a technology researcher and AI content specialist with more than seven years of experience studying automation, machine learning models, and digital innovation. He has worked with multiple tech startups as a consultant, helping them adopt smarter tools and build data-driven systems. Adrian writes simple, clear, and practical explanations of complex tech topics so readers can easily understand the future of AI.




